Коллекция компьютеров
О чем
Даный текст — это многоцелевая попытка рассказать историю компьтерной техники: задокументировать развитие и выделить генеалогию, попытаться рассказать о компьютере с точки зрения потребительской электроники, сформировать список лучших коллекционных экземпляров для строительства шоурумов или ютуб каналов. В качестве примера строится сборка Quadstellar на платформе X266 плате ASUS RAMPAGE VI.
История написания
Этот текст появился благодаря носталигии за PC культурой и возвращении к ее DIY истокам. Теперь, когда пришла старость, могу себе позволить воссоздать коллекцию компьютеров которыми владел в этой жизни. Авторский период 2010-2018 годов, который требовал только печатную машинку и процессор уровня ARM32, давно позади и теперь хочется занятся настоящими вычислительными задачами, которые требуют ресурсов уровня рабочих станций. В основном, я планирую заняться системами хранения на SSD/NVMe с использованием spdk и RocksDB/NVMe, а для строительства этих масивов нужны желательно невиртуальные диски, и побольше, ведь речь идет о 32 линиях PCI Express (PCIe) для дисковой подсистемы. Поэтому денег это все будет потреблять много, особенно с учетом желания работать на современном железе версии PCIe 4.0. Также хочу поэкспериментировать с системами индексации, которые работают в пространстве GPU (такими как Uber AresDB). Для этих целей нужны видеокарты с максимальным количеством памяти, а это обычно карты уровня Titan. К счастью, nVidia с анонсом 30-й серии снизила цены на такие карты в три раза (до $1500 за 24ГБ). Начиная с планов покупки этих современных дорогостоящих компонент я плавно войду в рестроспективу компьютерной техники (в том числе и свою личную) и прослежу историю ее развития с точки зрения стандарта PCIe, первая версия которого была создана в 2003 году. Все что до PCIe 1.0 не представляет для меня коллекционной ценности.
Обычно, на курсах системного программирования изучается какой-то булшит, какие-то несуществующие MIX процессоры, все это решительно я порицаю! Присоединяйтесь к унификации промышленности и академии в виде таких проектов как RISC-V, который тоже компонуется на шине PCI Express на примере таких плат как HiFive Unleashed Expansion Board со слотом x16 и своим PCIe свичем для периферии. PCIe также можно найти в легендарной октрытой платформе IBM POWER9, представленой такими материнскими платами как Talos II (PCIe 4.0 между прочим). Gigabyte давно уже делает ARM64 на платформе Marvel ThunderX2, тоже на PCIe. Я же считаю, что каждый системный программист должен понимать как устроен компьютер и как программируется PCI Express. Как минимум spdk — это прикладного уровня фреймворк, поэтому извинения не принимаются!
Что такое компьютер
Для начала хочу рассказать, что такое компьютер, с точки зрения каких критериев мы его представляем в этом выпуске. Компьютер — это система из следующих устройств: 1) процессор; 2) память; 3) видеокарта; 4) диск; 5) сетевая карта; 6) система питания и другие технические модули; которые соединены определенным образом (обычно это шина или непосредственное соединение точка-точка чере хаб (InfiniBand, PCIe, QPI, HyperTransport, etc). Эти соединения представляют собой видимые дорожки на материнской плате, где компонуется вся электроника. В случае PCIe такой хаб называется корневой комплекс, куда сходятся все линии PCIe. Основной принцип DYI электроники — это максимально гибкая система расширений, позволяющая добавлять дополнительные устройства в виде плат-расширений в специальные места которые подключены к шине или к хабу.
Виды таких систем соединения компонент называются платформы. Различают электрические (PCI, PCIe) и форм-факторные спецификации (PC/104, PCIe, mPCIe) платформ. PCIe вообще стала народной шиной, которая стала де-факто стандартом и при строительстве датацентров и на рынке потребителькой электроники, вытеснив такие, ранее казавшись перспективныыми, стандарты как InfiniBand или RapidIO. Теперь PCIe используется не только как соединение для массовых (Intel или AMD), но закрепилась и для более открытых (POWER9, ARM, RISC-V) микропроцессорных архиитектур.
Причины успеха PCIe
Причины такой популярности в действительно хорошей архитектуре электрической спецификации PCIe. В отличие от шины PCI, которая работает в общем случае как аппаратный брокер каналов, PCIe представляет собой систему из корневого комплекса и набора свичей которые можно подключать к нему каскадами. Эти устройства можно настроить таким образом, чтобы они передавали даные друг другу без участия посредников запрограммировав определенным образом роутинг корневого комплекса и системы PCIe свичей. Будучи сконфигурироваными, устройства могут использовать общую память и синхронизировать передачу даных между своими буферами (DMA). Представьте себе, что когда копируется файл с диска на диск, CPU при этом не пересылает никакие байты. Приблизительно то же происходит когда вы подключили две видеокарты в SLI режим, они общаются между собой по PCIe шине и способны обмениваться данными не требуя отвлечения процессора. Теоретически возможно подключение и сетевых карт к любым PCIe устройствам которые совместимы по атрибутам подключения, так сетевая карта может складировать пакеты на диск автоматически без участия процессора, который возможно позже прочитает эти данные асинхронным образом. К сожелению архитектурные ограничения асинхронной природы TCP/IP не позволяют делать такие чудеса в промышленном окружении, для этого желательно полностью перепроектировать сетевой уровень. Благодаря этим особенностям, которые ранее были доступны только в более дорогих оптических стандартах типа InfiniBand, вместе с понятной и гибкой системой масштабирования которая увеличивает пропускную способность дважды каждую версию, стандарт PCI Express продержался на рынке 17 лет и еще продержиться до момента схлопывания закона Мура в 2024 году (оринетировочно PCIe 7.0), когда мы достигнем 2нм техпроцесса с использованием нанотрубок.
Проблемы масштабирования PCIe в потребительской электронике
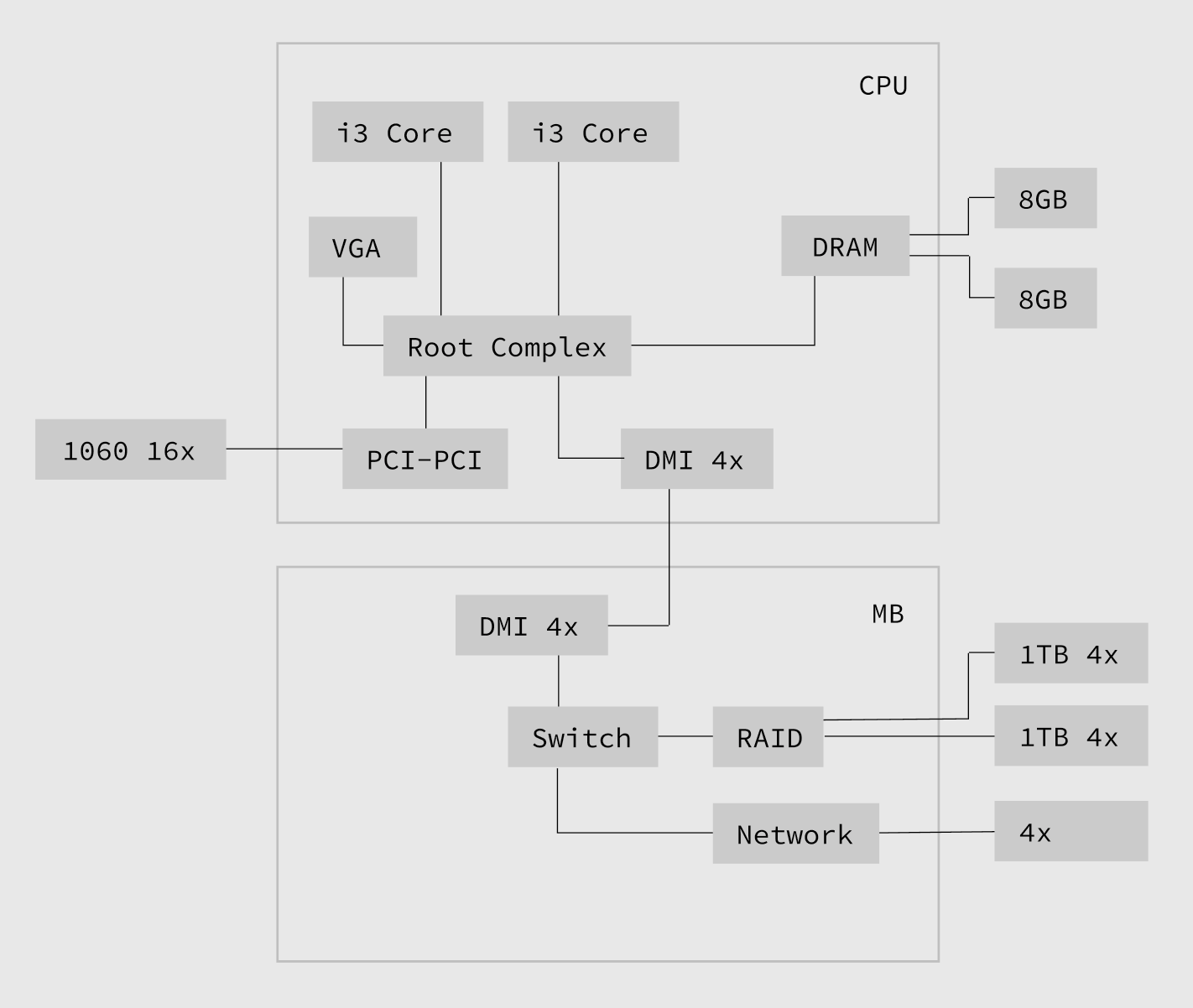
С помощью PCIe свичей распаивается система ввода-вывода для подключения внешних устройств. Обычно это подключается к проприетарному мосту и собственному протоколу, который соединяет корневой комплекс с системой свичей для внешних устройств. В случае Intel такой протокол называется DMI и имеет архитектурное ограничение в 4 PCIe линии и это не дает возможности строить эффективные RAID NVMe массивы на Intel платформе, которые обычно подключаются проприетарному мосту для внешних устройств через "бутылочное горлышко" DMI, которое, в свою очередь, подключено к корневому комплексу — это первая проблема масштабирования.
К счатью на материнских платах распаиваются слоты для видеокарт, которые подлючены не через DMI интерконнект, а напрямую к корневому комплексу через высокопроизводительный свич которые обычно виден как PCI-to-PCI мост. Вы можете использовтаь эти слоты для строительства дискового массива, но вы тогда лишаетесь возможности использовать GPU.
Другая проблема которая может возникнуть при масштабировании дискового массива — это количество PCIe линий, которые можно подключить к корневому комплексу, которые в современных системах находится прямо в процессоре.
И наконец существует третья проблема — это количество ядер в процессоре, если их очень мало, то каждое прерывание на линии будет требовать отвлечения процессора, что будет создавать много лишних преключений контекстов процессора и снижать общую теоретическую производительность. В идеальной синхронной системе, для контролья каждой PCIe линии нужно выделять отдельное ядро процессора, чтобы в случае прерывания возникшего при обмене данными между устройствами это никаким образом не влияло на работу остальных потоков системы (QoS на уровне линий PCIe). Таким образом хотелось бы процессор у которого ядер в два раза больше чем PCIe линий, потому как хочется же еще что-то считать. Это конечно жесткий оверкил, но только так можно достичь гарантий уровня систем реального времени. Именно такие эксперименты с дисковыми массивами меня и инетерсуют как продолжение моего исследования высокопроизводительных систем реального времени.
Структура коллекции
Свою коллекцию вижу как подрешетку нескольких измерений: 1) форм-фактор материнской платы: Mini-ITX (компактные), EEB/EATX/XLATX (рабочие станции); 2) тип микропроцессорной архитектуры: Intel, AMD, ARM64, POWER9, RISC-V; 3) версия PCIe: 3.0, 4.0 (версии, которые поддерживают NVMe M.2). Первые коллекционные, рассматриваемые мной чипсеты, это первые чипсеты для PCIe, которые имели графическую шину 16 PCIe линий и были созданы для первых процессоров Intel Core.
Intel Core ведет свою родословную от процессоров Intel Pentium Pro (P6). Поколения 32-битных x86 процессоров Intel: 1) i386; 2) i486, первые мои процессоры и первый Intel Datasheet который я прочитал от первой до последней страницы, у меня были и Intel и AMD чипы, а также AMD версия i586 с множителем FSB x5); 3) Pentium (P5, 1994), которое вошло на рынок почти одновременно со своими серверными, более мощными аналогами P6; 4) Pentium Pro (P6, 1995), Pentium II, Pentium III — эти процессоры имели общее архитектурное ядро, и развивались в основном в направлении мультимедийных расширений (MMX, SSE, которые стали прекурсорами современных AVX, NNI инструкций), экспериментах с сокетами и картриджами. В это время появились процессоры Xeon, с увеличиным объемом кешей.
Многосокетный период
У меня были двухпроцессорных материнские платы для картриджных (TYAN Tiger 133, Slot 1) и сокетных (TYAN Thunder, Socket 370) P6 процессоров, коллекция материнских плат на чипсете i440BX (ABit BP6, ASUS P2B), две легендарные оверклокерские материнские платы ASUS CUSL2 и TUSL2. Что сказать, я упарывался по дуальным мамкам на Intel тогда. К сожалению, а может к счатью эта часть коллекции утеряна и, судя по ценам на эти платы на вторичном рынке с учетом низкокачественной технологии производства конденсаторов того времени, восстанавливать ее я не собираюсь.
Пятая по счету архитектура 32-битных процессоров Intel — Pentium 4 NetBurst оказалась совершенно неудачной, хотели даже cменить стандарт на блоки питания (с ATX на BTX) из-за увеличеных показателей рассеиваемой мощности. Позже Intel отказалась от NetBurst архитектуры и за основу следующей архитектуры был взял P6. Следуюшая архитектура была уже 64-битной и получила название Intel Core, впервые появились VT-x, SSE3. Эта архитектура и живет в процессорах Intel и до сих пор и именно с процессоров Intel Core и чипсета Q35 начнется моя коллекция. Собирать будем комплектами по типу сокетов и чипсетов: материнская плата, максимальный процессор, максимальный альтернаьтивный процессор, максимальный объем ОЗУ.
Компактные системы
Компактными мы называем системы с количеством ядер от 4 до 16. Начиная с Intel Core стало понятно, что мосты, видеокарты, корневые комплексы, котроллеры памяти, когерентный кеш — все это лучше размещать прямо на кристале процессора. Многопроцессорные системы стали односокетными и популярной стала минитюаризация, рынок наполнился Mini-ITX платами и энергоэффетивность стала важнее производительности на пути прогресса.
Чипсет долгожитель для платформы Intel является Z370/X299, указан как единая спецификация, потому, что X299 и Z370 в смысле южных мостов одинковы с точки зрения программирования, они предлагают следующую модель распределения своих 30 HSIO линий чипсета (24 из которых мультиплексируются через свичи и лишь 16 из которых могут работать одноврменно):
Z370/X299. 1-6: USB, 7-9: USB/PCIe (3), 10: USB/PCIe/LAN (1), 11: PCIe/LAN (1), 12-14: PCIe (3), 15-16: PCIe/SATA (2), 17: PCIe (1), 18: PCIe/LAN (1), 19: PCIe/LAN/SATA (1), 20-24: PCIe/SATA (5), 25-26: PCIe (2), 27-30: PCIe RST (4).

Разница между X299 и Z370 лишь в количестве лининий, которыми может обладать процессор, и которые будут разведены на материнской плате к PCIe портам (желательно без свичей). Платформа X299 позваляет подключать к процессору 3 полных x16 слота или 48 линий. Если вам нужны 4 полных x16 слота, то для этого нужно переходить в платформу LGA3647/C261, где Xeon-W имеют как раз 64 линии. Для полноценного паралельного линка четырех x16 карт нужно 64 линии PCIe или это 16 дисков NVMe на которых можно построить RAID-0 на четырех M.2 x16 картах. Стоимость процессора с 48 линиями будет $1K, а материнская плата от $350 (Mini-ATX) до $700. Строить RAID-0 средствами VROC может быть даже выгодней, потому, что вряд ли какая-то RAID-0 карточка может быть лучше чем топовые Intel процессоры с мегабайтными кешами.
| Platform | x/PCIe/DMI | Motherboard | CPU | Alternative CPU |
|---|---|---|---|---|
| PGA1331/X570 | 24/4.0 | mITX STRIX X570-I | Ryzen 9 | |
| LGA1151/Z370 | 24/3.0/3.0 | mITX STRIX Z370-I | i7-8700K | i9-9900K |
| LGA2066/X299 | 24/3.0/3.0 | mITX X299E-ITX/ac | i7-9800X | i9-10980XE |
| LGA2011-v3/X99 | 8/3.0/2.0 | mITX X99E-ITX/ac | i7-6950X | E5-4669 v4 |
| LGA1150/Z97 | 8/3.0/2.0 | mITX MAXIMUS VII IMPACT | i7-4790K | E3-1286 v3 |
| LGA1155/Z77 | 8/3.0/2.0 | mITX P8Z77-I DELUXE | i7-3770K | E3-1245 v2 |
Несколько комментариев по поводу это таблицы. Здесь собраны шесть плат на пяти чипсетах, покрывающие потребительские процессоры AMD и Intel. Это такая игра: собрать минимальное количество материнских плат, в которые можно вставить любой процессор. После Z370 я перестал обновлятся, так как не считаю новые чипсеты достойные апгрейда, пока не выпустятся новые серверные аналоги чипсетов. Z390 отличается от Z370 только поддержкой 64ГБ RAM и USB 3.2 портом дополнительным. Z490 просто смена сокета, хотя эти же процессоры 10-й серии можно получить на прошлой X299 платформе, да еще и более мощные с большим количеством PCIe линий. Вообщем вы как хотите, а я коллекциоными Z390 и Z490 не считаю, хотя от нового STRIX Z390-I не отказался бы для своего 9900K, чтобы запаковать его до 64GB RAM.
| Codename | CPU | Cores | Lanes | Motherboard |
|---|---|---|---|---|
| Broadwell | E5-2699V4 | 22 | 40 | X99E-ITX/ac |
| Haswell | E5-4669V3 | 18 | 40 | X99E-ITX/ac |
| Zen 3 | Ryzen 9 | 16 | 24 | STRIX X570-I |
| Coffee Lake | i9-9900K | 8 | 16 | STRIX Z370-I |
| Coffee Lake | i7-8700 | 6 | 16 | STRIX Z370-I |
| Haswell | E3-1286V3 | 4 | 16 | MAXIMUS VII IMPACT |
| Ivy Bridge | E3-1245V2 | 4 | 16 | P8Z77-I DELUXE |
Что касается AMD, то к счастью она привела именование своих потребительских продуктов в соотвествии с линейкой Intel, модели Ryzen 3, 5, 7, 9. Это аналоги линейки Intel Core с количество ядер до 16. Все эти процессоры (Zen+, Zen 2, Zen 3) можно установить в mITX материнскую плату ASUS ROG STRIX X570-I c лучшим на рынке VRM. Вообще платы mITX лучше для разгона.
Как видите в легендарную X99E-ITX/ac можно воткнуть Xeon процессоры с 18 и 22 ядрами. Любое использование процессора на платформе Mini-ITX, потребление которого больше 65W на мой взгляд несбалансировано и является предметом исключительно энтузиазма и спортивного интереса. Если мне понадобится что-то посчитать, я буду увеличивать не мегагерцы, а количество ядер, да до такой степень, чтобы плюс минус пара ядер была уже не важна. Именно поэтому в этом обзоре вообще не упоминается устройство тактового генератора, важного элемента любого компьютера. Тогда пришлось бы рассказать про устройство адаптивной SpeedStep технологии которая регулирует напряжением на ядрах, частотой интерконекта и памяти. Канальность в памяти это как RAID с дисками, чем их больше чем быстрее может быть пямять, поэтому в бенмарках выигрывают древние Xeon с четырехканальными, а в некоторых случаях шести-канальными контроллерами памяти. При сборке Mini-ITX системы я бы прежде всего уделил внимание энергопотреблению, а потом уже выжал максимальную мощность — это стимулирует покупать современное оборудование. Правилом хорошего тона для Mini-ITX систем считаются блоки питания 600W уровня Titanium, желательно безвентиляторные. Такие БП существуют, я пользуюсь БП Seasonic, которые стояли в первых IBM PC (который у меня тоже был). Все что выше 600W — это энтузиазм. Например использование 9900K в Mini-ITX — это энтузиазм.
Рабочие станции
Рабочими станциями мы называем системы с количеством ядер больше 16. На рынке серверных процессоров увеличение ядер шло еще более бодрыми темпами, для увеличивающегося количества PCIe линий, нужно было больше ядер, и это стало основным приоритетом для эволюции действительно многоядерных архитектур. Mac Pro на платформе LGA3647 (Xeon-W) были построены с ипользованием чипсета C261, поэтому если хочется максимально оригинальный Хакинтош, то DOMINUS EXTREME за $1800 звучит как разумный выбор :-) Я сосредоточил свой фокус на Альфа и Омеге материнских плат для рабочих станций от ASUS.
| Platform | x/PCIe/DMI | Motherboard | CPU | Alternative CPU |
|---|---|---|---|---|
| LGA4094/TRX40 | 88/4.0 | ZENITH II EXTREME ALPHA | 3990X | |
| LGA3647/C621 | 64/3.0/3.0 | DOMINUS EXTREME | W-3275 | Platinum 8280 |
| LGA2066/X299 | 48/3.0/3.0 | RAMPAGE VI EXTREME OMEGA | i9-10980XE |
LGA3647 платорфма предназначена для Xeon процессоров семейств W и Platinum, которые ведут свою родословную не от Pentium Pro (P6), а от многоядерных Xeon Phi, где каждое ядро это Atom процессор, представленный ранее как энергоэффективный x86 конкурент ARM процессора.
| Codename | CPU | Cores | Lanes | Motherboard |
|---|---|---|---|---|
| Zen 3 | 3390X | 64 | 88 | ZENITH II EXTREME ALPHA |
| Cascade Lake | Xeon Platinum 8280 | 28 | 48 | DOMINUS EXTREME |
| Cascade Lake | W-3275 | 28 | 64 | DOMINUS EXTREME |
| Skylake | Xeon Platinum 8180 | 28 | 48 | DOMINUS EXTREME |
| Skylake | W-3175X | 28 | 48 | DOMINUS EXTREME |
| Cascade Lake | i9-10980XE | 18 | 48 | RAMPAGE VI EXTREME |
| Skylake | i9-9800X | 8 | 44 | RAMPAGE VI EXTREME |
AMD начала выпускать энергоэффективные многоядерные (от 32) процессоры на Zen 3 архитектуре только через 7 лет (в 2017) после появления Xeon Phi процессоров. Зато сразу дали 88 PCIe линий, версию 4.0 и без проприетарном моста (DMI), почти все линии заведены сразу на корневой комплекс.

Intel пришлось сделать ответный шаг на Threadripper и выпустить 10-е поколение Cascade Lake для платформы X299, чтобы продлить свой цейтнот. Я думаю специально для этой эмиссии 10-го поколение X-серии ASUS выпустила дополнительную серию плат RAMPAGE VI EXTREME OMEGA, подчеркивая момент уходящей платформы.
Рабочая станция на платформе X299
В качестве платформы была выбрана серия ASUS Rampage VI. На примере сериии материнских плат Rampage VI для X-Series процессоров Intel покажем как производители компонуют PCIe линии.
Первая плата Rampage VI Apex была представлена на COMPUTEX в 2017 году. Через пол года вышла версия с U.2 портом Rampage VI Extreme. Через два года, на CES в 2019 была представлена плата Rampage VI Omega с более минималистичной PCIe разводкой ориентированной на NVMe массивы. Так же через пол года на GAMESCOM в 2019 году была представлена обновленная версия платы без U.2 порта Rampage VI Extreme Encore. Я самостоятельно восстановил конфигурации этих материнских плат для процессоров с 48 PCIe линиями, использовал при этом их руководства пользователя.
RAMPAGE VI APEX Q1 2017
Достаточно классическая и минималистичная конфигурация с двумя полными x16 слотами и еще одним дисковым массивом для VROC на DIMM.2 слоте на два NVMe x4. И еще остается один x4 PCIe слот для карты расширения, куда можно вставить NVMe x4. Таким образом можно сказать что эта плата спроектирована для процессоров с 44 линиями и позволяют строить SLI x16 конфигурации + VROC 3x RAID-0.

RAMPAGE VI EXTREME Q3 2017
На мой взгляд переусложненная конфигурация с большим количеством PCIe свичей, но с дополнительной опцией в виде U.2 порта (правда придется пожертвовать одним диском в VROC массиве), и дополнительного M.2 сокета на X299 чипсете, который обычно используется для загрузочных дисков.

RAMPAGE VI EXTREME OMEGA Q1 2019
Омега вернула былую простоту разводки APEX, так же есть M.2 слот на X299 и U.2 слот, который так же конфликтует с 3x VROC массивом, но при этом не с DIMM с еще одним дополнительным M.2 разеведенный на процессор. Второй M.2 конфликтует с PCIe x4 слотом.

RAMPAGE VI EXTREME ENCORE Q3 2019
Последняя ревизия платы без U.2 слота, с обеими M.2 дисками разведенными на X299. Плата сохранила традиционную для Rampage VI емкость 32 полный PCIe линий и возможность строительства VROC массива на 3 диска.

[1]. Intel® Core™ 8th, 9th and Intel® Xeon®E Processor Families #1
[2]. Intel® Core™ 8th, 9th and Intel® Xeon®E Processor Families #2
[3]. Intel® 200 Series: B250, Q250, H270, Q270, Z270, X299, Z370, H310, B365 PCHs #1
[4]. Intel® 200 Series: B250, Q250, H270, Q270, Z270, X299, Z370, H310, B365 PCHs #2
[5]. Intel® 300 Series: H310, B365, B360, B370, Q370, Z370, Z390 PCHs #1
[6]. Intel® 300 Series: H310, B365, B360, B370, Q370, Z370, Z390 PCHs #2
Видеокарты
Что касается экспериментов с системами индексации, которые располагаются в памяти GPU, то здесь имеет смысл играться только с памятью от 10ГБ, т.е. не ниже 1080 Ti. Все карточки, что имеют меньше памяти годятся только для игрушек и то не больших.
| Model | PCIe | Chip | Memory | Process | Transistors |
|---|---|---|---|---|---|
| GTX 780 Ti | 3.0 | GK110 | 3GB DDR5 | 28nm | 7080M |
| GTX 980 Ti | 3.0 | GM200 | 6GB DDR5 | 28nm | 8B |
| GTX 1080 Ti | 3.0 | GP102 | 11GB DDR5 | 16nm | 12B |
| RTX 2080 Ti | 3.0 | TU102 | 11GB DDR6 | 12nm | 18.6B |
| RTX 3090 | 4.0 | GA102 | 24GB DDR6 | 8nm | 28B |
Видеокарты это второй вид вычислительных мощностей после CPU. Современные компьютеры это аналог таких систем как BeBox или Cell/BE, которые могут совмещать вычислительные CISC, RISC, SIMD или VLIW блоки. Процессоры видеоркарт называются GPU и, как и обычные процессоры CPU, имеют свой набор инструктий и свою локальную память. Аналог инструкции MOV выступает команда копирования в/из DMA буфера в DDR памяти по PCIe. Как и в CPU, в GPU есть ALU инструкции (сложение, умножение) и инструкции управления потоками выполнения.
CUDA и RDNA
Главные ядра CUDA [1] называются потоковыми процессорами (SM), их количество определяет производительность. Каждый SM состоит из многих скалярных процессоров, каждый из которых можно выделить для обработки вершин, фиугр, или пикселей. Для управления скалярными процессорами как потоками выполнения используется высокоуровневая модель паралельного программирования по типу SIMD, только источники и цели операций это не ячейки памяти, а потоки выполнения — SIMT.
В картах AMD используется другой набор инструкций [2], но все очень похоже. Буфера памяти разделяются на три типа: вершины, фигуры и пиксели. Команды GPU — это вычисления которые используют один тип памяти как источник, и другой тип памяти как цель команды. Вершинные шейдеры производят вычисления на вершинах и записывают результат в кольцевой буфер примитивов (массивы фигур). Геометрические шейдеры производят вычисления на буферах геометрических примитивов и записывают результат в память фрагментов, которые представляют собор растеризированый кусок экрана в буфере. Фрагмен становится пикселем когда переносится в реальный буфер экрана (пиксельные шейдеры). На каждом этапе такого пайп лайна вычислительные ядра пользуются текстурами, которые уже загружены в память GPU.
[1]. PTX ISA 7.0 (2020)
[2]. RDNA ISA 1.0 (2020)
[3]. CMU CS 15-462 Lecture 19 (2011)
Дисковые массивы
Для экспериментов в рамках проекта RocksDB/NVMe нам понадобятся карты PCIe x16 (4 слота M.2 каждый по x4 линии), для версий PCIe 3.0 и 4.0. Каждая такая карта конфигурируется как RAID-0 массив, и таким образом увеличивается скорость передачи линейно в 4 раза. Нам нужны именно RAID-0 массивы, потому что производительность — это главная мотивация проекта RocksDB/NVMe. Конечно таких карты это нужно вставлять в PCIe слот, подключенный напрямую к корневому комплексу, а не к проприетарному мосту для подключения периферии. Обычно половина слотов (а на mITX иногда и все) M.2 расположеных на материнских платах платформы Intel, подключены именно по такой шине DMI, которая имеет пропускную способность всего 4 PCIe линии, поэтому RAID-0 на таких слотах строить смысла нет. В случае ATX и EATX плат для построение RAID-0 лучше всего вставлять платы расширения для M.2 массивов в PCIe x16 слоты подключенные к корневому комплексу. В случае mITX систем, придется вытаскивать на время GPU и вставлять M.2 RAID-0 в единственный x16 слот.
M.2 слоты подключенные к проприетарному мосту типа DMI, можно использовать для единичных x4 NVMe инстансов, как загрузочные диски для альтернативных ОС и т.д. Я планирую использовать Haiku, FreeBSD, Linux, Windows. Не пропадать же M.2 слотам.
Есть еще вариант использования RocksDB/SATA, строим массив на дисках, максимальная пропускная способность которых всего 600МБ/c. Для этого на mITX системах можно построить массив из 3-4 дисков, а для больших ATX/EATX систем я советую покупать материнские платы, где есть 10 SATA портов.
Эти 10 портов обычно используют для RAID систем, но не аппаратных (потому, что восстанавливать любой RAID это нетривиальная задача), а программных комплексов типа Unraid, Ceph, GlusterFS. Ceph кстати использует RocksDB/NVMe бекенд для одного из типов своих хранилищ BlueStore). Эти системы предлагают более удобный нежели аппаратный способ работы с массивами: если один диск полетел, вы просто его вытаскиваете и вставляете новый.



Никаких причин (кроме бедности) использовать механические накопители в современном мире нет. Если вам сказали, что твердотельные накопители не стоит использовать для бекапа. то это действительно правда, но вместо механических накопителей обычно использовали магнитные ленты или магнитооптику, которая до сих пор является самым актуальным способом хранения данных, как например SONY PRO ODS-D380U.
За 10 лет цена на SSD снизилась с $1 за 1ГБ до $1 за 10ГБ. Твердотельные накопители NVMe состоят из DRAM кеша, SLC кеша и обычно 64-слойных TLC или QLC чипов. Некоторые проивзодители (ADATA, Transcend) используют технологию HMB и поставляют диски без DRAM кеша, вместо этого предполагается использование памяти хоста, которая подключена к PCIe. Такие диски не работают в Thunderbolt переходниках USB-to-PCIe. Нужно покупать только те NVMe которые предлагают показателти производительности близкие к теоретическому пределу PCIe 3.0 x4 (3938.5МБ/с), и максимально не зависят от обьема передаваемых данных (SLC кеш), DRAM кеш на 1Т обычно составляет 1ГБ. В 2020 году покупать NVMe меньше 1Т смысла нет, они быстрее, в них больше SLC кеша, более качественные микросхемы, выгодная удельная стоимость единицы объема.
| Model | PCIe | Size | Chip | Flash | MB/s | Lifetime |
|---|---|---|---|---|---|---|
| Samsung 970 EVO+ | 3.0 x4 | 1T | Samsung Phoenix | 64 TLC Samsung 256G | 3500/3300 | 600T |
| Samsung 970 PRO | 3.0 x4 | 1T | Samsung Phoenix | 64 MLC Samsung 256G | 3500/3300 | 1200T |
| WS Black SN750 | 3.0 x4 | 1T | SanDisk | 64 TLC SanDisk 256G | 3470/3000 | 600T |
| Patriot VPN100 | 3.0 x4 | 1T | Phison PS5012-E12 | 64 TLC Toshiba 256G | 3450/3000 | 1665T |
| Intel 760P | 3.0 x4 | 1T | SMI SM2262 | 64 TLC Intel 256G | 3230/1625 | 576T |
| ATADA XPG S11 Pro | 3.0 x4 | 1T | SMI SM2262EN | 64 TLC Micron 512G | 3500/3000 | 640T |
| Transcend MTE220S | 3.0 x4 | 1T | SMI SM2262EN | 64 TLC Micron 512G | 3500/2800 | 640T |
| Kingston KC2000 | 3.0 x4 | 1T | SMI SM2262EN | 96 TLC Toshiba 512G | 3200/2200 | 600T |
| Sabrent Rocket | 4.0 x4 | 1T | Phison PS5016-E16 | 96 TLC Toshiba 512G | 5000/4400 | 1800T |
| Corsair Force MP600 | 4.0 x4 | 1T | Phison PS5016-E16 | 96 TLC Toshiba 512G | 4950/2500 | 1800Т |
| FireCUDA 520 | 4.0 x4 | 1T | 96 TLC Toshiba 512G | 5000/4400 | 1800Т | |
| ADATA GAMMIX S50 | 4.0 x4 | 1T | Phison PS5016-E16 | 96 TLC Toshiba 512G | 5000/4400 | 1800Т |
Коллекционными считаются четырехканальные RAID-0 переходники на 16 линий PCIe, т.е. четыре диска (если меньше — не берите). Если на материнской плате остаются свободные х8 слоты и хочется их использовать для RAID, то можно использовать x8 M.2 адаптеры на два диска.
| Model | PCIe |
|---|---|
| ASUS Hyper M.2 V2 | 3.0 x16 |
| ASUS Hyper M.2 | 4.0 x16 |
| ASRock ULTRA QUAD | 3.0 x16 |
| AORUS Gen4 AIC | 4.0 x16 |
| Startech x8 Dual M.2 | 3.0 x8 |
| Sonnet M.2 4x4 | 3.0 x8 |
| Synology M2D18 | 4.0 x8 |
[1]. SPDK.IO/DOC
[2]. NVMe 1.4
[3]. Yan Beyer. A fast kvstore based on spdk programing framework.
[4]. T.Yoshimura, T.Chiba, H.Horii. EvFS: User-level, Event-Driven File System for Non-Volatile Memory.
Сеть
Корпуса
Как видно из таблиц, все платы можно разделить на две категории: маленькие и большие. В категории малых корпусов мне больше всего понравились DeepCool Tristellar, NZXT H200i, AZZA Pyramyd 804. Для полноразмерных больших CEB/EEB/XLATX плат — Lian Li O11D XL, а для EATX плат и дисковых массивов — DeepCool Quadstellar. Всего 5 корпусов. Если хватает денег можно еще купить стол Lian Li.
Итоговая конфигурация
— (1) GamerStorm DeepCool Quadstellar
— (2) Seasonic Platinum 1000W
— (3) Intel i9-10980XE 3GHz
— (4) G.SKILL 128GB 3600 CL17 8x16GB GTZR
— (5) ASUS STRIX LC 360
— (6) ASUS RAMPAGE VI EXTREME OMEGA
— (7) Samsung 970 EVO+